Las 3 Vs y tecnologías del Big Data, que un Data Scientist Junior quiere saber sobre la gestión de datos pero no se atrevía a preguntar
Hemos estado viendo la importancia de la figura del Data Scientist, como imprime la búsqueda, “el tono” de lo que desea lograr en el torrente de datos estructurados que se generan y almacenan a diario. Para ser un científico de datos de una start up y no morir el intento deberás tener claro y manejar todo el proceso de los datos: desde su generación , cómo y dónde se almacenan, qué tipo de análisis trabajarás y cómo pondrás a trabajar tu resultado (normalmente alguna predicción). Curiosamente en la industria por ejemplo, gran parte de trabajo consiste en la consecución de los datos brutos (un muy alto % del trabajo) por varias fuentes para su posterior “cocinado”.
Combinación de 3 factores
Hay que tener en cuenta también que, a fecha de hoy, 2019, nos movemos en un entorno en el que ha habido una combinación de 3 factores que llevaron a ese resultado:
- La reducción de coste y en tamaño de almacenaje (cabe más en menos) así como la proliferación de sensores (IoT) que hacen posible que el Big Data Analysis sea asumible y
- El modo masivo: el volumen, la velocidad y variedad de soportes de información. En concreto en 2019 los datos no estructurados (emails, video, audio, chats, posts, social media, etc) son el 80% de los datos que recogen las empresas y crecen a doble velocidad que los datos estructurados 10 años atrás. Esto modifica por completo la forma de almacenamiento ya que antes no jugaban en la ecuación las 3 V’s.
Veamos las principales tecnologías de datos que un Data Scientist debe manejar:
1. Bases de datos relacionales
Las primeras son las RDBMS (Relational Data Base Management Systems), lo que viene siendo el DBase_III o DBase_IV, y más tarde el Access de toda la vida. Son un conjunto de tablas con un esquema rígido que define características y atributos de cada campo, así como un sistema de filas y columnas para facilitar el acceso a los datos. La seguridad y certeza de los datos es fundamental para este tipo de BBDD. También se les reconoce por el acrónimo (ACID) es decir son Atomizadas, consistentes, aislados y durables o ACID-Compliant -que logran imponiendo una serie de restricciones en la carga de datos. Son perfectas para almacenar y gestionar datos contables, órdenes, pedidos etc. Como contrapartida no funcionan o no son eficientes con datos no estructurados o semiestructurados. Son más latosas de configurar, mantener y escalar. Para terminar, solo están diseñadas para correr en un terminal por lo que según que carga de datos realicemos, es muy lento. Vamos, que no están en la cima del mundo hoy en día…
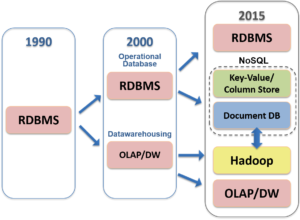
2. Bases de datos no relacionales
Con el boom de internet a partir de 2000 las necesidades de los players y su necesidad exponencial de crecimiento de datos, nacen las NoSQL o bases de datos no relacionales. Así Google crea MapReduce, Amazon: DynamoDB, Yahoo: Hadoop, Facebook: Cassandra y Hive. Algunos lo hicieron en código abierto y eso les hizo crecer más todavía. Las NoSQL, son alérgicas a los esquemas y estructuras y proveen sobre todo de flexibilidad al poder tratar datos estructurados y semiestructurados. Sin embargo, no todo es de color de rosa: estas NoSQL no son ACID-Compliant. Pero ¿qué nivel de consistencia necesitaban? Es decir, si Google no te da la óptima respuesta al 100% pero te la da al 99,99% ¿es suficiente? Por supuesto que en el entorno financiero no es suficiente, pero en el resto de entornos… sí que lo era… MongoDB es la más popular NoSQL database del merado y fue capaz de generar mucho valor a ciertas empresas que sentían que iban por caminos de tierra en lugar de por autopistas. Así por ejemplo en MetLife tras años de intentos de generar una BBDD tradicional con datos estructurados que gestionara todos sus productos, un empleado en un hackathon interno montó uno bajo NoSQL en unas horas y fue puesto en el mercado en 90 días.
3. Almacenamientos
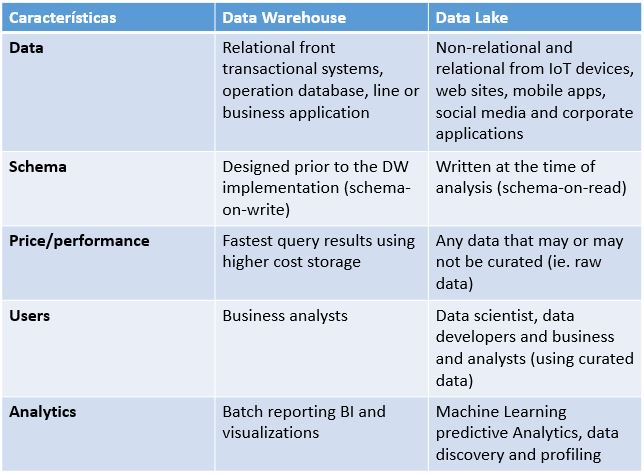
Data Warehouse – Data Lake – Data Swamp. Pero el ritmo de crecimiento siguió creciendo y trabajar todos los datos de la empresa con diferentes BBDDs se vio que era ineficiente. Una solución llamada Data Warehouse nació. Esta centraliza todos los datos de todas las bases de datos de distintas fuentes (interna y externa) de la empresa en un solo repositorio y facilitando el flujo de datos desde las operaciones a las tomas de decisión e insights del negocio. Pero necesitan ser procesadas antes de ser almacenadas lo que añadía mucho tiempo y personal al proceso. Así que surgieron los Data Lake: que almacenan datos brutos estructurados o no y a cualquier escala de tamaño. Pueden ser cargados sin necesidad de configuración ni estructura. Tienen el peligro que pueden acabar siendo más que lagos… ciénagas (Data Swamp).
4. Distributed & Paralell Processing
Hadoop, Spark & MPP. Todo lo visto anteriormente no es posible realizarlo con un ordenador ordinario y puede llevar semanas… así que había que interconectar muchos ordenadores compartiendo las BBDDs por “n” ordenadores o commodity servers (clusters). Ello logró nuevas economías. Apache Hadoop es un ejemplo de infraestructuras de datos distribuidos que permite el trabajo masivo de datos y facilita la arquitectura de “lagos”. Hadoop está diseñado para computar iterativamente escaneando cantidades masivas de datos en una operación en disco, distribuirla por su red de nodos y almacenar el resultado de nuevo en disco. Resultado lo que antes costaba 4 horas, se obtiene en 12 segundos. Aun así no puede realizar cálculos en tiempo real (al trabajar en batches). Así que lanzaron Apache Sparks en 2012 que procesa con memoria interna. Pero cuando la RAM se colapsa no se avanza gran cosa. Y nos queda la MPP, este distribuye el procesado de datos por nodos igualmente, y cada nodo, lo procesa en paralelo con multiprocesadores para ganar tiempo. Sin embargo casi todos los MPP no puede trabajar datos no estructurados e incluso los estructurados precisan de algo de cocina para ser aptos en la estructura con el consiguiente incremento de tiempo y recursos. La Bolsa de Nueva York migrando a una BBDD de MPP, eso sí, redujo sus tiempos de análisis en 8 horas.
5. La Nube
Las plataformas en la nube ofrecen servicios de almacén e infraestructura de BBDDs “pagas lo que consumes” encargándose del hardware, software y mantenimiento y otros servicios. Las Public Cloud, eliminan la inversión en capital en el momento inicial pudiendo dedicar sus recursos al core del negocio democratizando y reduciendo barreras de entradas al Big Data. Las Private Cloud son dedicadas a un solo cliente con necesidades especiales. Y por supuesto coexisten las híbridas: en la publica se trabajan datos no vitales y en la private los datos críticos de la empresa alojada.
UADIN Business School junto con UDIMA Universidad a Distancia de Madrid - Máster de Industria 4.0
Si deseas conocer nuestra formación de Industria 4.0 con el Máster de Capacitación en Industria 4.0 y Transformación Digital, puedes solicitar información o bien visitar la página donde se explica el contenido del máster junto con los profesores de primera categoría que lo imparten, donde me incluyo como coordinador del Máster.
Máster de Capacitación en Industria 4.0 y Transformación Digital